Introduction to Data Lakes - unlocking the power of unstructured data
What are data lakes, how they differ from data warehouses, and the benefits they offer
What are data lakes, how they differ from data warehouses, and the benefits they offer

In the age of data-driven decision-making, businesses are constantly seeking innovative ways to harness the power of data. Traditional data storage solutions, such as hierarchical data warehouses, have limitations that make them unsuitable for modern use cases. This has led to the emergence of a new approach called data lakes, which provide businesses with a scalable, cost-effective, and flexible solution for managing and analyzing large volumes of data.
As the world becomes increasingly driven by data, businesses are looking for ways to make sense of the vast amounts of information they possess. One solution that has become increasingly popular is the data lake. In this article, I will explain what are data lakes, how they differ from data warehouses, and explore the benefits they bring to the table. We'll also take a closer look at the components that make up a data lake, best practices for building and managing one, common challenges when implementing a data lake, and tools and technologies you can use to implement one.
A data lake is a centralized repository that stores vast amounts of data in its native, raw format. Unlike hierarchical data warehouses that organize data in files or folders, a data lake adopts a flat architecture and leverages object storage to store data. Object storage stores data along with metadata tags and unique identifiers, making it easier to locate and retrieve data across regions, resulting in improved performance.
Data lakes are designed to address the limitations of traditional data warehouses. While data warehouses offer highly performant and scalable analytics, they are often expensive, proprietary, and incapable of handling modern use cases. In contrast, data lakes enable organizations to consolidate all their data in a single, central location without the need for imposing a schema upfront. Data lakes can store raw data alongside structured, tabular data sources and intermediate data tables, making them capable of processing all data types, including unstructured and semi-structured data like images, video, audio, and documents.
There are several compelling reasons to consider using a data lake as part of your data management and analytics strategy:
Despite these advantages, data lakes come with their own set of challenges. Lack of support for transactions, data quality enforcement, governance, and poor performance optimizations are reasons data lakes often turn into data swamps. To overcome these challenges and unlock the full potential of data lakes, organizations have started adopting a new approach called Lakehouse.
A lakehouse is a solution that addresses the limitations of data lakes by adding a transactional storage layer on top. It combines the best features of data lakes and data warehouses, enabling traditional analytics, data science, and machine learning to coexist within a single system. The lakehouse approach allows businesses to perform a variety of cross-functional analytics, business intelligence, and machine learning tasks, unlocking massive business value.
With a lakehouse, data analysts can query the data lake using SQL to extract rich insights. Data scientists can join and enrich data sets, enabling them to build more accurate machine-learning models. Data engineers can build automated ETL (Extract - Transform - Load) pipelines, simplifying data integration and transformation processes. Business intelligence analysts can create visual dashboards and reporting tools faster and easier than ever before. All these use cases can be performed simultaneously on the data lake, even as new data streams in, without the need to transfer or duplicate data.
To build a successful lakehouse, many organizations are turning to Delta Lake, an open-format data management and governance layer that combines the strengths of both data lakes and data warehouses. Delta Lake provides enterprises with a reliable, single source of truth, enabling collaboration and breaking down data silos. It delivers high-quality, reliable, secure, and performant analytics for both streaming and batch operations.
Delta Lake is designed to address common challenges associated with data lakes, such as data quality, reliability, security, and performance. By leveraging Delta Lake, businesses can build a cost-efficient and highly scalable lakehouse that eliminates data silos and empowers end-users with self-serving analytics capabilities.
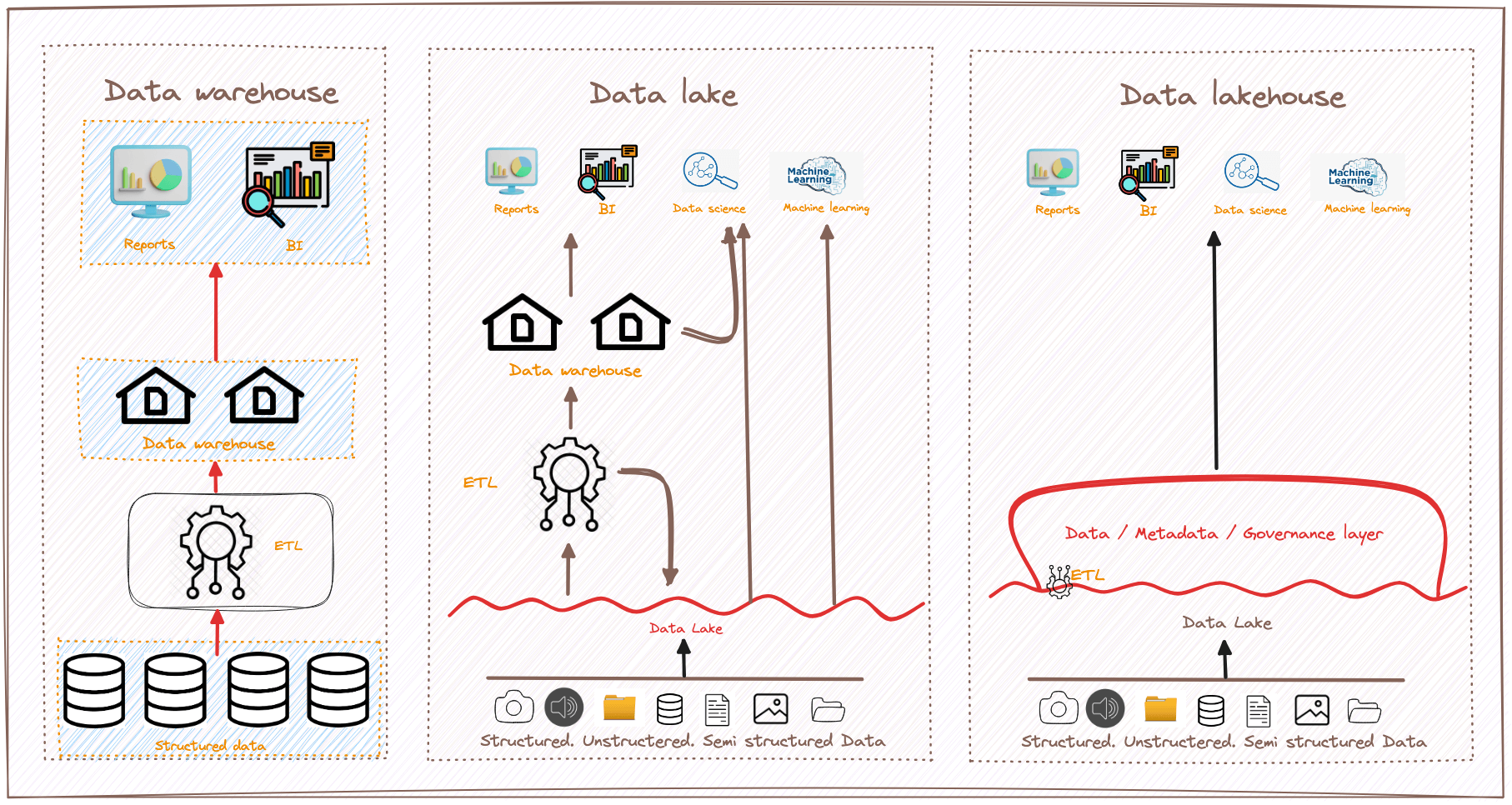
To better understand the differences between data lakes, data lakehouses, and data warehouses, let's compare them across various dimensions:
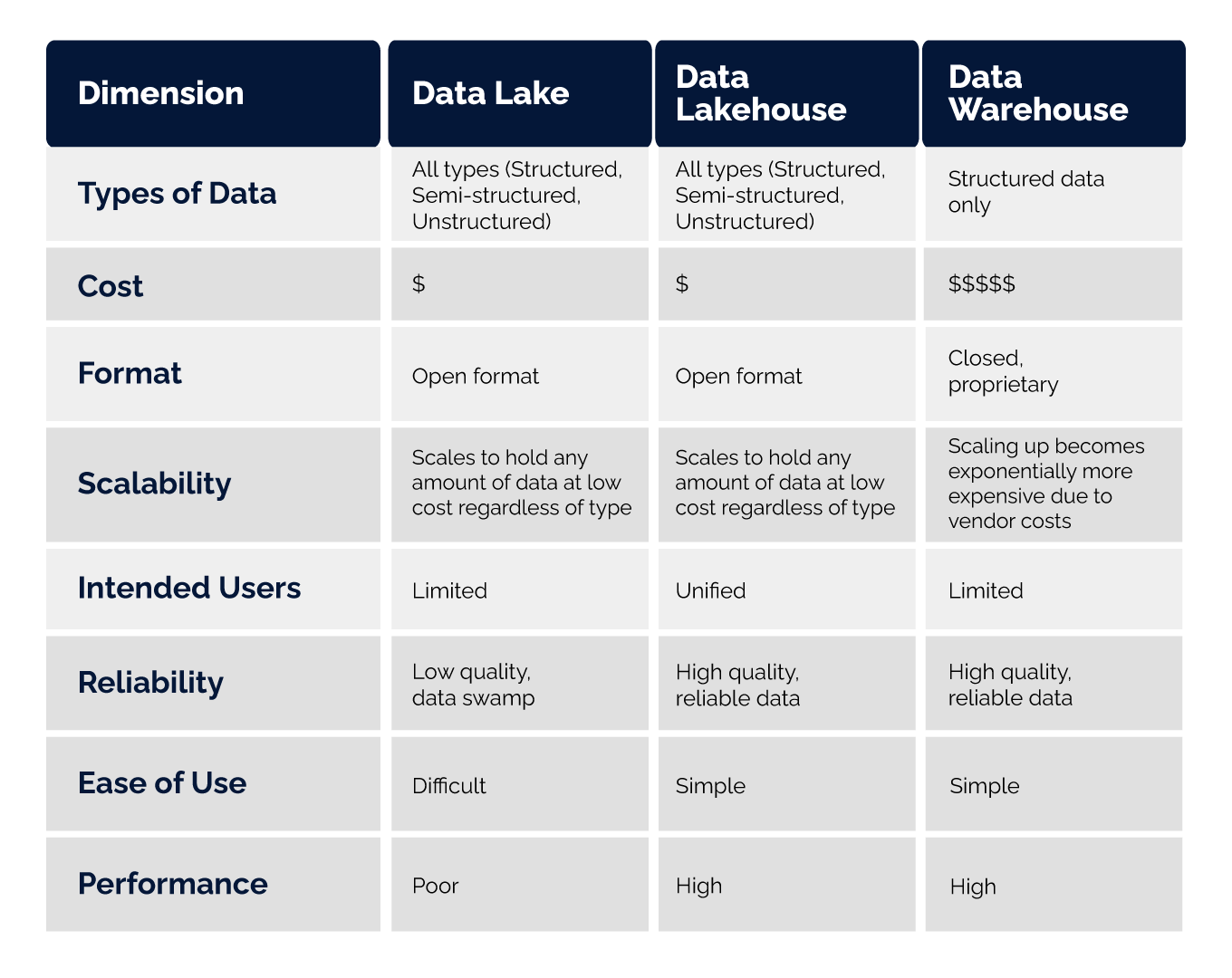
As the table illustrates, data lakes accommodate all types of data, making them suitable for diverse use cases. However, they often lack reliability and ease of use, leading to data swamps. Data warehouses, on the other hand, excel at processing structured data and offer high-quality, reliable data but at a significantly higher cost. The lakehouse approach combines the simplicity and structure of a data warehouse with the broader use cases and flexibility of a data lake, providing businesses with the best of both worlds.
To ensure a successful lakehouse implementation, here are some best practices to consider:
By following these best practices, businesses can maximize the value of their lakehouse implementation and empower their teams to derive meaningful insights from their data.
Data lakes have revolutionized how businesses store, manage, and analyze data. With their ability to handle diverse data types and their cost-effectiveness, data lakes have become a popular choice for organizations looking to leverage advanced analytics and machine learning. However, the challenges associated with data lakes, such as poor performance and lack of governance, have led to the emergence of the lakehouse approach.
A lakehouse combines the best features of data lakes and data warehouses, enabling businesses to perform a wide range of analytics and machine learning tasks in a unified and efficient manner. By adopting a lakehouse approach and leveraging technologies like Delta Lake, organizations can break down data silos, improve data quality, and empower their teams with self-serving analytics capabilities. As we learned here at Oceanobe, with t he right strategies and best practices in place, businesses can unlock the full potential of their data and gain a competitive edge in today's data-driven world.



